If you are on the rush of finding the solution, scroll down all the way to the end.
We were developing a feature, in which, we had to configure the host machine IP address on a remote machine so that the remote machine can pull data at its ease. As the host machine is connected to multiple networks, the challenge is to identify the right network interface that is accessible by the remote machine and configure the corresponding IP address on the remote machine. If we fail to pass on the right network interface to the receiver, our whole purpose of building that feature will be collapsed. So it turned out to be an unprecedented requirement for us to solve.
For the purpose of illustration, let us assume that we have two networks connected to the machine and one of the two networks is a public network and the other is a private network.
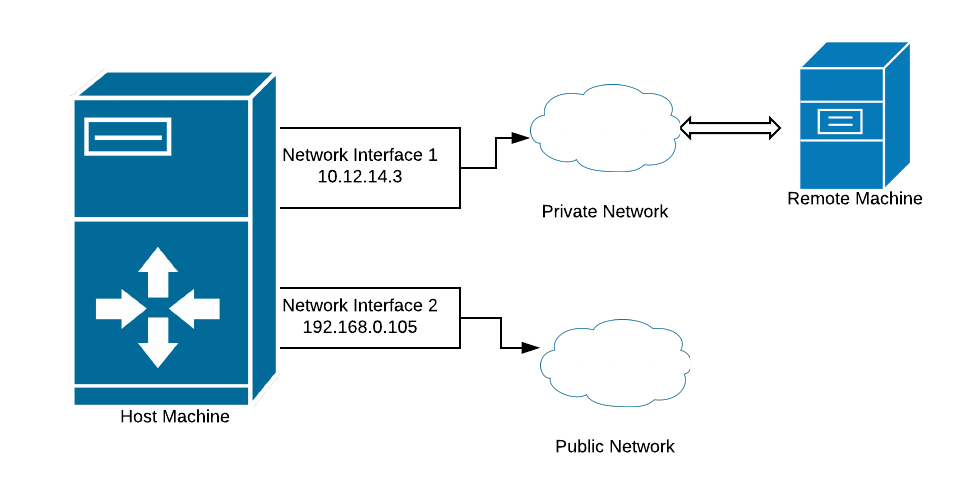
Given this setup, our goal was to find the network interface the packet takes to reach its destination. A bit of schooling - If a packet wants to reach a host located in a private network, will take Network Interface 1 as its exit route, likewise a packet takes Network Interface 2 to reach a host in public network.
Our first thought solution was to leverage the Routing table. Fortuitously, we found the Linux command in no time to query the routing table to extract the desired information (network interface). By formatting the command with the destination host IP address we will be able to figure out the network interface a packet takes to reach the destination host. The ip route command looks like the command below.
1
ip route get 172.217.160.132
That seems to be an easy-peasy solution to the problem! Isn’t it? Integrating the raw ip route command programmatically just as the snippet below solves the problem.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// cmd = "ip route get 172.217.160.132"
func exe_cmd(cmd string, wg *sync.WaitGroup) {
parts := strings.Fields(cmd)
head := parts[0]
parts = parts[1:len(parts)]
out, err := exec.Command(head, parts...).Output()
if err != nil {
fmt.Printf("%s", err)
}
fmt.Printf("%s", out)
wg.Done()
}
The output will look similar to the below output.
1
172.217.160.132 via 172.17.0.1 dev eth1 src 172.17.0.2
The caveat with this approach is that you have to parse the output string to extract out the necessary information. Unfortunately, this process will turn out to be more painful in case of any error like network going down or not connected to the internet. Even if it’s plausible for us to parse for any possible output, it will eventually fail to meet the coding standards leaving the reviewers’ eyebrows frowned. We realized that we got to look for a neat and impeccable solution.
Further exploring led us to a very convincing solution in all the ways. The sub-package routing of gopacket gave us everything that we felt wanting in the previous approach. It prevented our code to give a room for string parsing logic and escaped us from damaging the readability of the code. As an added bonus, we enjoyed the ease of handling any errors on using routing package.
Without anything stopping us further, we jumped on to using routing sub-package leaving the Linux Command approach as an ephemeral hero.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
func determineRouteInterface(serverAddr string) error {
var ip net.IP
if ip = net.ParseIP(serverAddr); ip == nil {
return fmt.Errorf("error as non-ip target %s is passed", serverAddr)
}
router, err := routing.New()
if err != nil {
return errors.Wrap(err, "error while creating routing object")
}
_, gatewayIP, preferredSrc, err := router.Route(ip)
if err != nil {
return errors.Wrapf(err, "error routing to ip: %s", serverAddr)
}
fmt.Printf("gatewayIP: %v preferredSrc: %v", gatewayIP, preferredSrc)
return nil
}
The output of the above code snippet will look similar to the below output.
1
gatewayIP: 172.17.0.1 preferredSrc: 172.17.0.2
With no surprise, the output is very neatly present eliminating the need for fancy string parsing logic.
In the first place, we were totally surprised to see a package available in Golang to query the routing table on a Linux machine. We understood that the problem of determining a network interface a packet takes to reach the destination is very rare and least underscored on the web. Hence, we decided to bring the routing package to the light. Indeed, this blog post was a result of our excitement on finding a package to fetch routing information from an underlying routing table on a Linux machine ;)